سيوضح هذا الدليل كيفية استخدام VectorStoreRetrieverMemory باستخدام إطار عمل LangChain.
كيفية استخدام VectorStoreRetrieverMemory في LangChain؟
VectorStoreRetrieverMemory هي مكتبة LangChain التي يمكن استخدامها لاستخراج المعلومات/البيانات من الذاكرة باستخدام مخازن المتجهات. يمكن استخدام مخازن المتجهات لتخزين البيانات وإدارتها لاستخراج المعلومات بكفاءة وفقًا للموجه أو الاستعلام.
للتعرف على عملية استخدام VectorStoreRetrieverMemory في LangChain، ما عليك سوى الاطلاع على الدليل التالي:
الخطوة 1: تثبيت الوحدات
ابدأ عملية استخدام مسترد الذاكرة عن طريق تثبيت LangChain باستخدام الأمر pip:
نقطة تثبيت لانجشين
قم بتثبيت وحدات FAISS للحصول على البيانات باستخدام بحث التشابه الدلالي:
نقطة تثبيت faiss-GPU 
قم بتثبيت وحدة chromadb لاستخدام قاعدة بيانات Chroma. يعمل كمخزن متجه لبناء الذاكرة للمسترد:
نقطة تثبيت chromadb 
هناك حاجة إلى وحدة tiktoken أخرى لتثبيتها والتي يمكن استخدامها لإنشاء الرموز المميزة عن طريق تحويل البيانات إلى أجزاء أصغر:
نقطة تثبيت tiktoken 
قم بتثبيت وحدة OpenAI لاستخدام مكتباتها لبناء LLMs أو chatbots باستخدام بيئتها:
نقطة تثبيت openai 
قم بإعداد البيئة على Python IDE أو الكمبيوتر المحمول باستخدام مفتاح API من حساب OpenAI:
يستورد أنتيستورد com.getpass
أنت . تقريبًا [ 'OPENAI_API_KEY' ] = com.getpass . com.getpass ( 'مفتاح واجهة برمجة تطبيقات OpenAI:' )
الخطوة 2: استيراد المكتبات
الخطوة التالية هي الحصول على المكتبات من هذه الوحدات لاستخدام مسترد الذاكرة في LangChain:
من com.langchain. حث يستورد قالب موجهمن التاريخ والوقت يستورد التاريخ والوقت
من com.langchain. llms يستورد OpenAI
من com.langchain. التضمينات . openai يستورد OpenAIEmbeddings
من com.langchain. السلاسل يستورد ConversationChain
من com.langchain. ذاكرة يستورد VectorStoreRetrieverMemory
الخطوة 3: تهيئة متجر المتجهات
يستخدم هذا الدليل قاعدة بيانات Chroma بعد استيراد مكتبة FAISS لاستخراج البيانات باستخدام أمر الإدخال:
يستورد فايسمن com.langchain. docstore يستورد InMemoryDocstore
# استيراد المكتبات لتكوين قواعد البيانات أو مخازن المتجهات
من com.langchain. com.vectorstores يستورد فايس
#إنشاء التضمينات والنصوص لتخزينها في مخازن المتجهات
embedding_size = 1536
فِهرِس = فايس. مؤشرFlatL2 ( embedding_size )
embedding_fn = OpenAIEmbeddings ( ) . embed_query
com.vectorstore = فايس ( embedding_fn , فِهرِس , InMemoryDocstore ( { } ) , { } )
الخطوة 4: بناء المسترد مدعومًا بمتجر Vector
قم ببناء الذاكرة لتخزين أحدث الرسائل في المحادثة والحصول على سياق الدردشة:
المسترد = com.vectorstore. as_retriever ( search_kwargs = قاموس ( ك = 1 ) )ذاكرة = VectorStoreRetrieverMemory ( المسترد = المسترد )
ذاكرة. save_context ( { 'مدخل' : 'أنا أحب أكل البيتزا' } , { 'انتاج' : 'رائع' } )
ذاكرة. save_context ( { 'مدخل' : 'أنا جيد في كرة القدم' } , { 'انتاج' : 'نعم' } )
ذاكرة. save_context ( { 'مدخل' : 'أنا لا أحب السياسة' } , { 'انتاج' : 'بالتأكيد' } )
اختبر ذاكرة النموذج باستخدام المدخلات المقدمة من المستخدم مع سجله:
مطبعة ( ذاكرة. Load_memory_variables ( { 'اِسْتَدْعَى' : 'ما هي الرياضة التي يجب أن أشاهدها؟' } ) [ 'تاريخ' ] ) 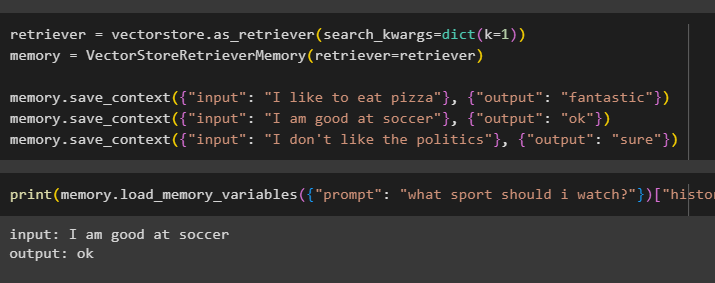
الخطوة 5: استخدام المسترد في سلسلة
الخطوة التالية هي استخدام مسترد الذاكرة مع السلاسل عن طريق بناء LLM باستخدام طريقة OpenAI() وتكوين قالب المطالبة:
LLM = OpenAI ( درجة حرارة = 0 )_القالب الافتراضي = '''التفاعل بين الإنسان والآلة
ينتج النظام معلومات مفيدة مع تفاصيل باستخدام السياق
إذا لم يكن لدى النظام الإجابة لك، فهو ببساطة يقول ليس لدي الإجابة
معلومات مهمة من المحادثة:
{تاريخ}
(إذا لم يكن النص ذا صلة فلا تستخدمه)
الدردشة الحالية:
إنسان: {إدخال}
الذكاء الاصطناعي:'''
اِسْتَدْعَى = قالب موجه (
input_variables = [ 'تاريخ' , 'مدخل' ] , نموذج = _القالب الافتراضي
)
# قم بتكوين ConversationChain () باستخدام قيم معلماتها
المحادثة_مع_الملخص = ConversationChain (
LLM = LLM ,
اِسْتَدْعَى = اِسْتَدْعَى ,
ذاكرة = ذاكرة ,
مطول = حقيقي
)
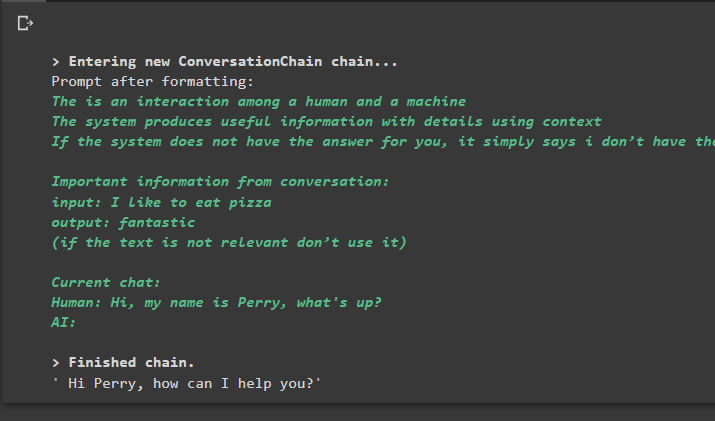
المحادثة_مع_الملخص. يتنبأ ( مدخل = 'مرحبا، اسمي بيري، ما الأمر؟' )
انتاج |
يؤدي تنفيذ الأمر إلى تشغيل السلسلة وعرض الإجابة المقدمة من النموذج أو LLM:
تابع المحادثة باستخدام الموجه المستند إلى البيانات المخزنة في متجر المتجهات:
المحادثة_مع_الملخص. يتنبأ ( مدخل = 'ما هي رياضتي المفضلة؟' ) 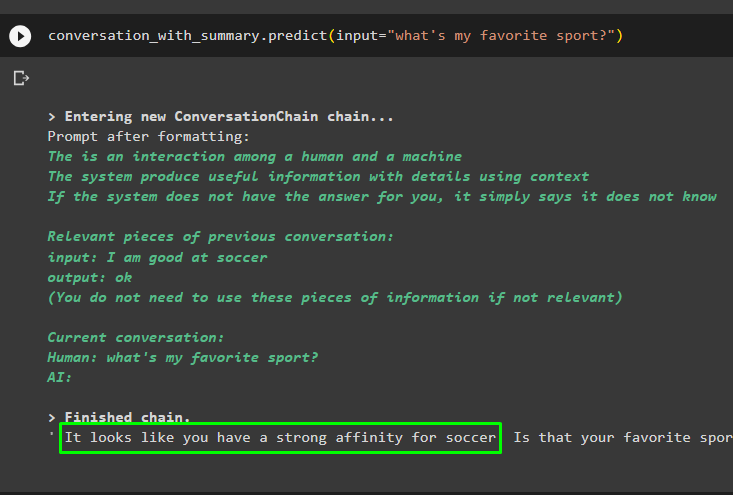
يتم تخزين الرسائل السابقة في ذاكرة النموذج والتي يمكن للنموذج استخدامها لفهم سياق الرسالة:
المحادثة_مع_الملخص. يتنبأ ( مدخل = 'ما هو طعامي المفضل' ) 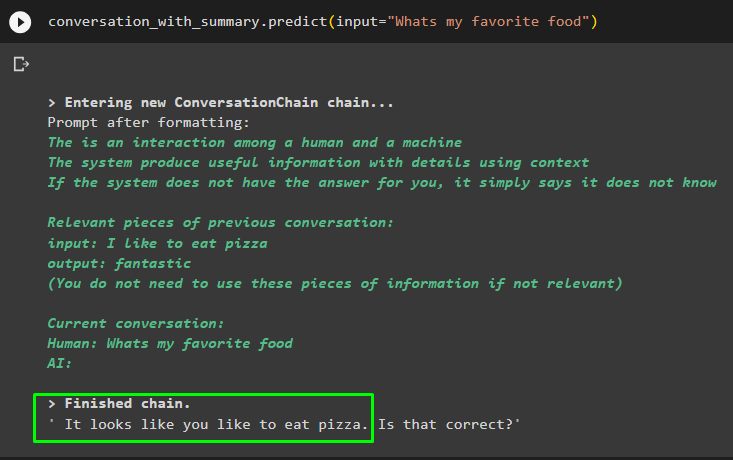
احصل على الإجابة المقدمة للنموذج في إحدى الرسائل السابقة للتحقق من كيفية عمل مسترد الذاكرة مع نموذج الدردشة:
المحادثة_مع_الملخص. يتنبأ ( مدخل = 'ما هو اسمي؟' )قام النموذج بعرض المخرجات بشكل صحيح باستخدام بحث التشابه من البيانات المخزنة في الذاكرة:
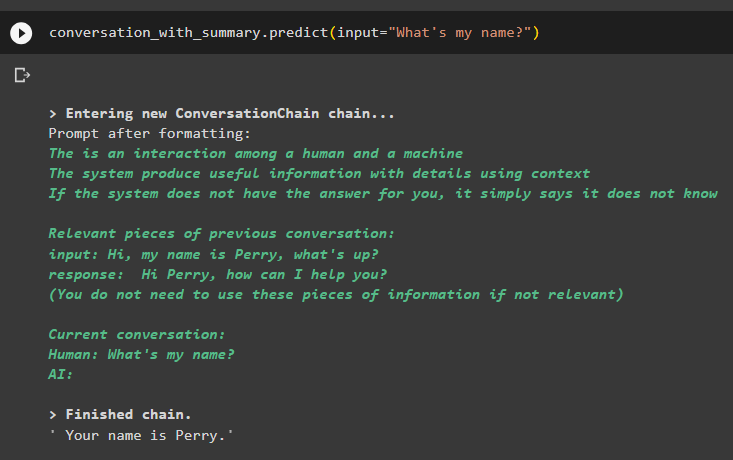
يتعلق الأمر كله باستخدام مسترد متجر المتجهات في LangChain.
خاتمة
لاستخدام مسترد الذاكرة استنادًا إلى مخزن المتجهات في LangChain، ما عليك سوى تثبيت الوحدات وأطر العمل وإعداد البيئة. بعد ذلك، قم باستيراد المكتبات من الوحدات النمطية لإنشاء قاعدة البيانات باستخدام Chroma ثم قم بتعيين قالب المطالبة. اختبر المسترد بعد تخزين البيانات في الذاكرة من خلال بدء المحادثة وطرح الأسئلة المتعلقة بالرسائل السابقة. لقد تناول هذا الدليل بالتفصيل عملية استخدام مكتبة VectorStoreRetrieverMemory في LangChain.