تقوم طريقة 'Series.to_csv ()' في Pandas بإخراج كائن السلسلة المحدد بترميز قيم مفصولة بفواصل (csv). تأخذ هذه الوظيفة القيم من سلسلة وتعديل تنسيقها عن طريق إضافة فواصل للفصل بين قيم الفهرس والعمود.
لاستخدام هذه الوظيفة ، يتعين علينا استخدام الصيغة التالية:

ستزودك هذه المقالة بتقنيتين مختلفتين لتعلم طرق استخدام هذه الطريقة في برنامج بيثون.
المثال رقم 1: استخدام طريقة Series.to_csv () لتحويل سلسلة مع فهرس التاريخ والوقت إلى قيم مفصولة بفواصل
لتعديل سلسلة إلى تنسيق CSV ، سنستخدم وظيفة 'Series.to_csv ()'. سينشئ هذا الرسم التوضيحي سلسلة مع DatetimeIndex ثم يحولها إلى تنسيق قيم مفصولة بفاصلة.
لتشغيل هذه الطريقة ، يجب أن يكون لدينا أداة تدعم برمجة Python. تم اختيار أداة 'Spyder' لتجميع الرموز. لكتابة البرنامج النصي عليه ، أطلقنا أولاً الأداة المثبتة في نظامنا. يحتاج برنامج Python إلى مكتبة لممارسة أساليبها لتحقيق النتيجة المطلوبة. المكتبة التي قمنا بتحميلها هنا هي 'الباندا'. في نفس سطر الكود ، يتم تحديد الاسم المستعار لهذه المكتبة على أنه 'pd'. لذلك ، في أي مكان في البرنامج ، نحتاج إلى كتابة 'pandas' للوصول إلى وظيفة. بدلاً من ذلك نكتب 'pd'.
الخطوة الأولى للبدء بالكود هي إنشاء سلسلة Pandas. نحتاج إلى كتابة 'pd' لاستخدام طريقة إنشاء السلاسل من الباندا. يتم استدعاء الوظيفة 'pd.Series ()' لإنشاء سلسلة بالقيم المحددة. القيم التي قدمناها للمسلسل هي 'اسطنبول' و 'إزمير' و 'أنقرة' و 'أنقرة' و 'أنطاليا' و 'قونية' و 'بورصة'. إذا كنت تريد تسمية مجموعة القيم هذه ، يمكنك القيام بذلك باستخدام معلمة 'الاسم'. هنا ، قمنا بتسمية هذه المجموعة من القيم 'مدن' لأنها تحمل أسماء 6 مدن. لتخزين هذه السلسلة ، تم إنشاء كائن سلسلة 'تركيا'.
لإنشاء فهرس DatetimeIndex ، قمنا باستدعاء طريقة “pd.date_range ()”. بين أقواس هذه الوظيفة ، مررنا 4 وسيطات هي: 'البدء' و 'التكرار' و 'النقاط' و 'tz'.
تأخذ الوسيطة 'البدء' تاريخًا ووقتًا لبدء إنشاء نطاق زمني منها. هنا ، حددنا تاريخ ووقت البدء كـ '2022-03-02 02:30'. تعمل المعلمة 'التكرار' على تصنيف التكرار للنطاق الزمني. لذلك ، قدمنا لها القيمة 'D'. الآن ، سيتم إنشاء نطاق زمني على التردد اليومي. يتم تعيين وسيطة 'الفترة' على '6' مما يعني أنها ستنشئ نطاقًا زمنيًا لمدة 6 أيام. المعلمة الأخيرة هي 'tz' والتي تحدد المنطقة الزمنية للمنطقة المحددة. لقد حددنا المنطقة الزمنية لـ 'Asia / Istanbul'.
لتخزين هذا النطاق الزمني ، قمنا بإنشاء متغير 'Datetime'. لتعيين DatetimeIndex ، استخدمنا خاصية 'Series.index'. يتم توفير اسم السلسلة 'تركيا' مع خاصية '.index' وتعيين نطاق التاريخ والوقت المخزن في متغير 'التاريخ والوقت' لها. وبالتالي ، فإن خاصية 'index' ستأخذ القيم من متغير 'Datetime' وتجعلها قائمة الفهرس لسلسلة 'Turkey'. أخيرًا ، لعرض سلسلة المخرجات ، استخدمنا طريقة 'print ()' ومررنا سلسلة 'Turkey' كمدخل إليها لعرض محتواها.
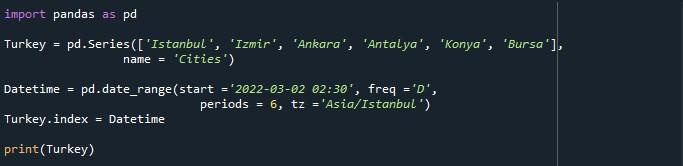
لقد ضغطنا للتو على خيار 'تشغيل الملف' لتنفيذ البرنامج النصي. وبالتالي ، يمكننا أن نرى سلسلة مع DatetimeIndex تبدأ من '2022-03-02 02: 30: 00 + 03: 00' وتنتهي في '2022-03-07 02: 30: 00 + 03: 00 مما يؤدي إلى إنشاء فترة 6 أيام. أسفل السلسلة 'التكرار: D' ، تم أيضًا ذكر اسم قائمة المصفوفة 'المدن' ونوع dtype 'الكائن'.
الآن ، سوف نتعلم تحويل هذه السلسلة التي رأيناها للتو في اللقطة أعلاه إلى تنسيق CSV. لتعديل السلسلة إلى قيم مفصولة بفواصل ، لدينا طريقة توفرها وحدة الباندا وهي 'Series.to_csv ()'. تأخذ هذه الطريقة قيم السلسلة المقدمة وتضيف الفواصل بين قيم العمود.
تسمى وظيفة 'Series.to_csv ()'. تم ذكر اسم السلسلة التي نريد تحويلها بالطريقة 'Turkey.to_csv ()'. للحفاظ على القيم المفصولة بفواصل ، قمنا بإنشاء متغير 'Comma_Separated' ثم وضعنا محتواه في نافذة الإخراج عن طريق استدعاء وظيفة 'print ()'.

ها هي سلسلتنا بصيغة csv. يمكننا أن نرى في اللقطة أنه تم فصل قيم الفهرس والقيم المتسلسلة باستخدام الفاصلات الموجودة فيهما.

المثال رقم 2: استخدام طريقة Series.to_csv () لتحويل سلسلة بقيم NaN إلى قيم مفصولة بفواصل
الأسلوب الثاني لممارسة طريقة 'Series.to_csv ()' هو تطبيق هذه الطريقة لتحويل سلسلة تحتوي على بعض الإدخالات الفارغة إلى تنسيق CSV.
لقد قمنا في البداية باستيراد الحزم الضرورية. يتم إنشاء 'pd' كاسم مستعار لـ pandas و 'np' كاسم مستعار لـ numpy. يتم تحميل مجموعة أدوات numpy هنا لأننا سنقوم بعمل بعض الإدخالات الفارغة في سلسلتنا باستخدام 'np.NaN' أثناء إنشائها باستخدام طريقة pd.Series () pandas.
يتم استدعاء وظيفة 'pd.Series ()' لبناء سلسلة من حيوانات الباندا بهذه القيم: 'Nile' و 'Amazon' و np.NaN و 'Ganges' و 'Mississippi' و 'np.NaN' و 'Yangtze' ، 'الدانوب' و 'ميكونغ' و 'np.NaN' و 'الفولغا'. يوجد إجمالي 21 قيمة محددة للسلسلة من بينها 3 إدخالات تحتفظ بقيم 'np.NaN' مما يعني أن 3 قيم مفقودة في السلسلة. تحدد خاصية 'الاسم' اسم مجموعة القيم هذه التي قدمناها 'العناوين'. يتم استخدام خاصية 'الفهرس' لتعيين قائمة الفهرس المعرفة من قبل المستخدم بدلاً من الذهاب مع القائمة الافتراضية.
هنا ، نريد قائمة الفهرس بالقيم '10' ، '11' ، '12' ، '13' ، '14' ، '16' ، '17' ، '18' ، '19' ، '20' ، و 21 '. الآن ، ستحتوي سلسلتنا على قائمة الفهرس التي تبدأ من '10' بدلاً من '0'. الآن ، قم بتخزين هذه السلسلة حتى نتمكن من استخدامها لاحقًا في البرنامج. لقد قمنا بتهيئة كائن متسلسل 'Rivers' وخصصنا له سلسلة الإخراج الناتجة عن استدعاء طريقة 'pd.Series ()'. يمكن رؤية السلسلة من خلال عرضها على الشاشة باستخدام وظيفة 'print ()' بواسطة python.
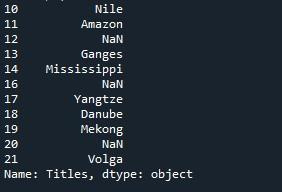
طبع الإخراج الذي تم تقديمه على الجهاز الطرفي سلسلة تبدأ قائمة فهرسها من 10 وتنتهي عند 21 مما يعني أن السلسلة تحتوي على 21 قيمة.
ستتحول السلسلة إلى تنسيق CSV باستخدام طريقة 'Series.to_csv ()'.
لقد استدعينا طريقة 'Series.to_csv ()' مع سلسلتنا 'تركيا'. ومن ثم ، ستأخذ هذه الطريقة القيم من سلسلة 'Turkey' وتحولها إلى تنسيق قيم مفصولة بفواصل. يتم حفظ النتيجة في المتغير 'Converted_csv'. وفي النهاية ، تتم طباعة السلسلة المحولة بمساعدة وظيفة 'print ()'.

في لقطة النتيجة أدناه ، يمكنك أن ترى أن قيم السلسلة قد تم تغييرها الآن بطريقة يتم فيها استخدام الفاصلة لفصلها عن قائمة الفهرس. علاوة على ذلك ، عندما تكون القيم مفقودة ، تتم طباعة رقم الفهرس فقط بفاصلة.

استنتاج
يعد تعديل سلسلة الباندا إلى تنسيق CSV نهجًا عمليًا. يمكن تحقيق ذلك باستخدام وظيفة الباندا 'Series.to_csv ()'. استخدم هذا الدليل طريقتين لاستخدام هذه الطريقة. في الرسم التوضيحي الأول ، استدعينا هذه الطريقة لتحويل سلسلة بمؤشر DatetimeIndex إلى تنسيق قيم مفصولة بفواصل. استخدم المثيل الثاني وظيفة 'Series.to_csv ()' لتعديل سلسلة مع بعض الإدخالات المفقودة في تنسيق CSV. تم تنفيذ كلتا التقنيتين عمليًا باستخدام أداة 'Spyder' على نظام التشغيل Windows.